从完全零基础开始教你写一个Python机器人!每天唯一秒回你的人!


私信菜鸟007获取此项目源码!提供航班信息连接客户和他们的财务作为客户支持可能性(几乎)是无限的。聊天机器人的历史可以追溯到1966年,当时韦森鲍姆发明了一种名为“伊丽莎”(ELIZA)的电脑程序。它......
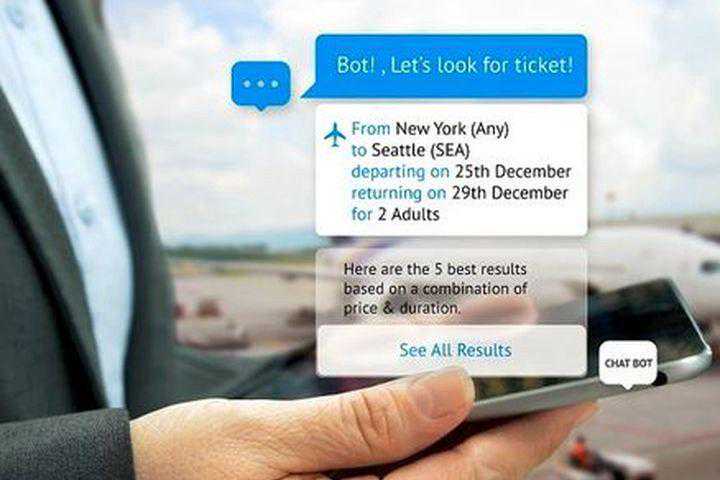


私信菜鸟007获取此项目源码!
提供航班信息
连接客户和他们的财务
作为客户支持
可能性(几乎)是无限的。
聊天机器人的历史可以追溯到1966年,当时韦森鲍姆发明了一种名为“伊丽莎”(ELIZA)的电脑程序。它仅仅从200行代码中模仿一个心理治疗师的言语。你现在仍然可以和它交谈:伊丽莎。


在本文中,我们将在python中基于NLTK库构建一个简单的基于检索的聊天机器人。
开始构建机器人
先决条件
具有scikit库和NLTK的实际操作知识。但是你如果是NLP新手,仍然可以阅读本文,然后参照参考资料。
NLP
研究人类语言和计算机交互的领域称为自然语言处理,简称NLP。它位于计算机科学、人工智能和计算语言学的交汇处(维基百科)。NLP是计算机分析、理解和从人类语言中获取意义的一种聪明且有用的方法。利用NLP,开发人员可以组织和结构化知识来执行诸如自动摘要、翻译、命名实体识别、关系提取、情感分析、语音识别和主题分割等任务。
NLTK:简要介绍
NLTK(自然语言工具包)是构建Python程序来处理人类语言数据的领先平台。它为超过50个语料库和词汇资源(如WordNet)提供了易于使用的接口,同时提供了一套用于分类、词语切分、词干、标记、解析和语义推理的文本处理库,这些都是工业强度NLP库的封装器。
NLTK被称为“使用Python进行计算语言学教学和工作的一个极好工具”,以及“一个与自然语言打交道的绝佳库”。
Python的自然语言处理提供了语言处理编程的实用介绍。我强烈推荐这本书给使用Python的NLP初学者。
下载及安装NLTK
安装NLTK:运行pipinstallnltk
测试安装:运行python接着输入importnltk
对特定平台的指令,点这。
安装NLTK包
导入NLTK然后运行().这将打开NLTK的下载程序,你可以从其中选择要下载的语料库和模型。也可以一次下载所有包。
用NLTK对文本进行预处理
文本数据的主要问题是它都是文本格式(字符串)。然而,机器学习算法需要某种数值特征向量来完成任务。因此,在我们开始任何NLP项目之前,我们都需对其进行预处理。基本文本预处理包括:
将整个文本转换为大写或小写,这样算法就不会将大小写的相同单词视为不同的单词
词语切分:指将普通文本字符串转换为符号列表的过程。也就是我们真正想要的词。句子分词器可用于查找句子列表,单词分词器可用于查找字符串形式的单词列表。
NLTK数据包包括一个用于英语的预训练Punkt分词器。
去除噪声,即所有不是标准数字或字母的东西。
删除停止词。有时,一些在帮助选择符合用户需要的文档方面似乎没有什么价值的常见单词被完全排除在词汇表之外。这些单词叫做停止词。
词干提取:词干提取是将词尾变化词(有时是派生词)还原为词干、词根或词根形式(通常是书面形式)的过程。例如,如果我们要提取下列词:“Stems”,“Stemming”,“Stemmed”,“andStemtization”,结果将是一个词“stem”。
词形还原:词干提取的一个细微变体是词形还原。它们之间的主要区别在于,词干提取可以创建不存在的词,而词元是实际的词。所以你的词根,也就是你最终得到的词,在字典里通常是查不到的,但词元你是可以查到的。词形还原的例子如:“run”是“running”或“ran”等词的基本形式,或者“better”和“good”是同一个词元,因此它们被认为是相同的。
单词袋
在初始预处理阶段之后,我们需要将文本转换为有意义的数字向量(或数组)。单词袋是描述文档中单词出现情况的文本表示。它包括两个东西:
•一个已知词汇表。
•一个对已知词存在的量度。
为什么它被称为一个单词袋?这是因为关于文档中单词的顺序或结构的任何信息都会被丢弃,模型只关心已知单词是否出现在文档中,而不关心它们在文档中的位置。
单词袋的直观感受是,如果文档的内容相似,那么文档就相似。此外,我们还可以从文档的内容中了解一些文档的含义。
例如,如果我们的字典包含单词{Learning,is,the,not,great},并且我们想向量化文本“Learningisgreat”,我们将有以下向量:(1,1,0,0,1)。
TF-IDF方法
单词袋方法的一个问题是,频繁出现的单词开始在文档中占据主导地位(例如,得分更高),但可能并没有包含太多的“有信息内容”。此外,它将给予较长的文档更多的权重。
一种方法是根据单词在所有文档中出现的频率重新调整单词的频率,以便对“the”等在所有文档中也经常出现的单词适当降低权重。这种评分方法称为检索词频率-逆文档频率,简称TF-IDF,其中:
检索词频率:是当前文档中单词出现频率的得分。
TF=(Numberoftimestermtappearsinadocument)/(Numberoftermsinthedocument)
逆文档频率:是这个词在文档中罕见度的得分。
IDF=1+log(N/n),where,Nisthenumberofdocumentsandnisthenumberofdocumentsatermthasappearedin.
Tf-idf权重是信息检索和文本挖掘中常用的一种权重。该权重是一种统计度量,用于评估单词对集合或语料库中的文档有多重要
例子:
余弦相似度
TF-IDF是一种在向量空间中得到两个实值向量的文本变换。然后我们可以通过取点积然后除以它们的范数乘积来得到任意一对向量的余弦相似度。接着以此得到向量夹角的余弦值。余弦相似度是两个非零向量之间相似度的度量。利用这个公式,我们可以求出任意两个文档d1和d2之间的相似性。
CosineSimilarity(d1,d2)=Dotproduct(d1,d2)/||d1||*||d2||
其中d1,d2是非零向量。
TF-IDF和余弦相似度的详细说明和实际例子参见下面的文档。
Tf-IdfandCosinesimilarity
…
现在我们对NLP过程有了一个基本概念。是我们开始真正工作的时候了。我们在这里将聊天机器人命名为“ROBO”
导入必备库
importnlt('punkt')first-timeuseonlysent_tokens=_tokenize(raw)convertstolistofwords让我们看看sent_tokens和theword_tokens的例子
['achatbot(alsoknownasatalkbot,chatterbot,bot,imbot,interactiveagent,orartificialconversationalentity)isacomputerprogramoranartificialintelligencewhichconductsaconversationviaauditoryortextualmethods.',['a','chatbot','(','also','known']预处理原始文本
现在我们将定义一个名为LemTokens的函数,它将接受符号作为输入并返回规范化符号。
lemmer=()#defLemTokens(tokens):return[(token)fortokenintokens]remove_punct_dict=dict((ord(punct),None))defLemNormalize(text):returnLemTokens(_tokenize(().translate(remove_punct_dict)))
关键字匹配
接下来,我们将通过机器人定义一个问候函数,即如果用户的输入是问候语,机器人将返回相应的回复。ELIZA使用一个简单的关键字匹配问候。我们将在这里使用相同的概念。
GREETING_INPUTS=("hello","hi","greetings","sup","what'sup","hey",)GREETING_RESPONSES=["hi","hey","*nods*","hithere","hello","Iamglad!Youaretalkingtome"]
defgreeting(sentence):():()inGREETING_INPUTS:(GREETING_RESPONSES)
生成回复
为了让我们的机器人为输入问题生成回复,这里将使用文档相似性的概念。因此,我们首先需要导入必要的模块。
从scikitlearn库中,导入TFidf矢量化器,将一组原始文档转换为TF-IDF特征矩阵。
_
同时,从scikitlearn库中导入cosinesimilarity模块
_similarity
这将用于查找用户输入的单词与语料库中的单词之间的相似性。这是聊天机器人最简单的实现。
我们定义了一个回复函数,该函数搜索用户的表达,搜索一个或多个已知的关键字,并返回几个可能的回复之一。如果没有找到与任何关键字匹配的输入,它将返回一个响应:“对不起!”我不明白你的意思"
defresponse(user_response):robo_response=''TfidfVec=TfidfVectorizer(tokenizer=LemNormalize,stop_words='english')tfidf=_transform(sent_tokens)vals=cosine_similarity(tfidf[-1],tfidf)idx=()[0][-2]flat=()()req_tfidf=flat[-2]
if(req_tfidf==0):robo_response=robo_response+"Iamsorry!Idon'tunderstandyou"returnrobo_responseelse:robo_response=robo_response+sent_tokens[idx]returnrobo_response
最后,我们将根据用户的输入来决定机器人在开始和结束对话时说的话。
flag=Trueprint("ROBO:,typeBye!")while(flag==True):user_response=input()user_response=user_()if(user_response!='bye'):if(user_response=='thanks'oruser_response=='thankyou'):flag=Falseprint("ROBO:Youarewelcome..")else:if(greeting(user_response)!=None):print("ROBO:"+greeting(user_response))else:sent_(user_response)word_tokens=word_tokens+_tokenize(user_response)final_words=list(set(word_tokens))print("ROBO:",="")print(response(user_response))sent_(user_response)else:flag=Falseprint("ROBO:Bye!takecare..")差不多就是这样。我们用NLTK中编写了第一个聊天机器人的代码。你可以在这里找到带有语料库的完整代码。现在,让我们看看它是如何与人类互动的:

尽管聊天机器人在某些问题上不能给出令人满意的答案,但在另一些问题上却表现得很好。
结论
虽然它是一个非常简单的机器人,几乎没有任何认知技能,但它是一个很好的方法来了解NLP和聊天机器人。虽然“ROBO”会对用户输入做出响应。但它愚弄不了你的朋友,对于一个生产系统,你可能希望考虑现有的机器人平台或框架之一,但是这个示例应该能够帮助你思考设计和创建聊天机器人的挑战。互联网充斥着大量的资源,在阅读了这篇文章之后,我相信你会想要创建一个自己的聊天机器人。快乐编程!!
本文链接:https://www.yaohaizhijun.cn/931134549596.html